1. 그룹 함수란?
테이블의 전체 행에 대해 하나 이상의 컬럼을 기준으로 그룹화 하여 그 그룹별로 결과를 출력하기 위한 함수
그룹 함수는 집계 함수와 함께 통계적인 결과를 출력하는 데에 자주 사용된다.
SELECT COLUMN, GROUP_FUNCTION(COLUMN)
FROM TABLE
[ WHERE CONDITION ]
[ GROUP BY GROUP_BY_EXP ]
[ HAVING GROUP_CONDITION ]
GROUP BY 절은 해당 절에 쓰이는 컬럼이나 표현식을 기준으로 하여 대상 테이블을 그룹화하게 되고,
HAVING 절은 GROUP BY 절에 의하여 생성된 그룹별로 조건을 걸게 된다.
2. 집계 함수
1️⃣ COUNT : 대상이 되는 행의 개수 출력
2️⃣ MAX : NULL 을 제외한 모든 행에서의 최대값 출력(출력되는 행은 한 줄)
3️⃣ MIN : NULL 을 제외하는 모든 행에서의 최소값 출력(출력되는 행은 한 줄)
4️⃣ SUM : NULL 을 제외하는 모든 행의 합
5️⃣ AVG : NULL 을 제외한 모든 행의 평균 값
1️⃣ COUNT
COUNT ({* | [ DISTINCT | ALL ] EXP })
테이블에서 조건을 만족하는 행의 개수를 반환하는 함수이다.

해당 질의 결과를 확인해보면 학생 중에는 지도 교수가 없는 학생이 존재한다.
이에 대하여 COUNT 함수를 적용해보면,
COUNT 함수는 NULL 을 무시하기 때문에 지도 교수가 없는 학생은 COUNT 대상이 되지 못 할 것이다는 예상을 할 수 있다.

지도 교수가 없던 학생 수는 총 6명이었고, 총 학생 수는 16명이었기 때문에 예상된 결과가 출력되었음을 확일할 수 있다.
즉 COUNT 함수는 WHERE 절에서 IS NOT NULL 을 사용한 것과 결과가 동일하다는 것이다.

2️⃣ MAX

학생 테이블에서 키에 관한 데이터를 출력한 결과이다.
학생 중 가장 큰 키를 출력하기 위해서는 MAX 함수를 활용할 수 있다.
해당 출력 결과에서 가장 큰 키는 186이다.

MAX 함수로 최대값이 출력된 것을 확인할 수 있다.
3️⃣ MIN
마찬가지로 키 데이터에서 최소값을 출력해보자.
예상 결과는 160이다.

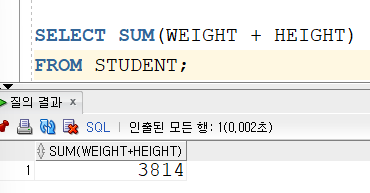
4️⃣ SUM
대상이 되는 데이터의 합계를 구하는 함수로 다음과 같이 사용할 수 있다.
.5️⃣ AVG
대상이 되는 데이터의 평균 값을 구하는 함수로 다음과 같이 사용할 수 있다.

3. 그룹화 만들기
그룹화 하기 위해서 대상이 되는 기준은 한국어로 ~별로 해석되는 것이라고 생각하면 된다.
예를 들어 교수 테이블에서 소속 학과별로 평균 급여를 구하는 경우에 바로 '소속 학과별'이 그룹화의 대상이 되는 것이다.
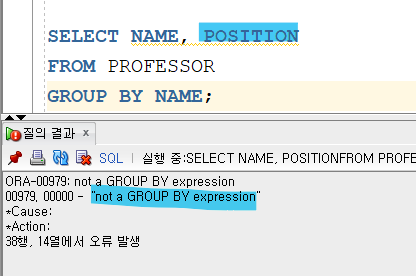
GROUP BY 절을 사용하게 되면 이 기준으로 그룹별 분류가 일어나기 때문에 해당 절에 명시하지 않은 칼럼은 집계 함수와 함께 사용할 수 없다.
GROUP BY 절을 사용하기 전에 먼저 WHERE 절에서 조건을 걸어 그룹 대상을 줄이는 것이 좋은데 이는 성능적으로 좋은 방법이다.
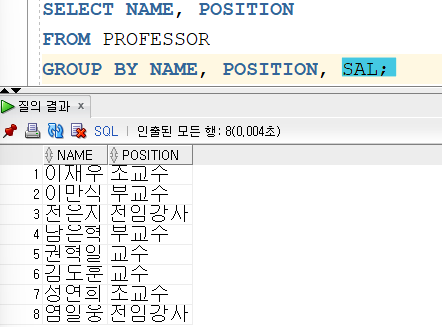
또한 SELECT 절에서 사용할 컬럼이나 표현식은 GROUP BY 절에서 반드시 명시해야 한다는 특징이 있다.
대신 GROUP BY 절에서 명시하였다고 해도 SELECT 절에 명시하지 않아도 된다.
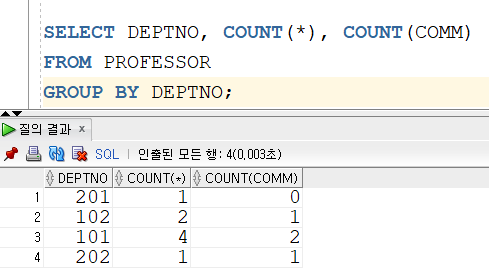
만약 교수 테이블에서 학과별로 교수 수와 보직 수당을 받는 교수 수를 출력하고자 한다면,
'학과별'이기 때문에 이를 기준으로 GROUP BY 하면 된다.
절에 대한 설명을 추가해보면
SELECT 절에는 출력 결과로 확인하고 싶은 내용을 추가하게 되기 때문에,
학과 번호, 해당 학과에 소속된 교수의 수, 해당 교수 중 보직 수당을 받는 교수의 수를 작성하였다.
FROM 절에서는 교수 테이블이기 때문에 PROFESSOR 를 작성하였다.
또한 GROUP BY 절에는 그룹화의 기준이 되는 학과 번호를 작성하였다.
4. 다중 컬럼을 이용한 그룹화
그룹화할 대상이 여러 개인 경우에는 어떻게 처리해야 할까?
하나 이상의 컬럼을 사용하여서 그룹을 나누고, 그룹화된 대상을 또다시 어떠한 기준으로 그룹화하는 것이다.
예를 들어 교수 테이블에서 교수에 대하여 학과별로 그룹화하고, 그 그룹화 된 데이터를 바탕으로 또다시 직급별로 다시 그룹화를 해 본다고 했을 때에 다음과 같이 할 수 있다.
먼저 학과별로 그룹화 했을 때에는 다음과 같이 나타난다.

교수의 소속 학과가 무엇이 있는지 그룹화 한 것이다.
여기에 각 학과별로 직급이 어떻게 구성되어 있는지 확인하려면 다음과 같이 할 수 있다.

이는 소속 학과별로 있는 교수의 직급을 좀 더 세분화 하여 구분한 것이다.
또다른 예시로 살펴보자.
이번에는 전체 학생을 소속 학과별로 1차 그룹화 하고, 같은 학과의 학생들을 학년별로 2차 그룹화한다.
그리고 출력 결과에는 학년, 학년별 인원수, 평균 몸무게를 출력하게 하는 것이다.
먼저 1차 그룹화를 해보자.

1차 그룹화에서는 소속 학과별을 대상으로 하기 때문에 SELECT 절에서도 소속 학과와 소속 학과의 인원수만 출력할 수 있다.
다음은 2차 그룹화를 해보자.

이번에는 소속 학과에 학년별 구성을 살펴볼 수 있게 되었다.
여기에 추가적으로 평균 몸무게를 추가하면 다음과 같다.

5. ROLLUP, CUBE 연산자
SELECT COLUMN, GROUP_FUNCTION(COLUMN)
FROM TABLE
[WHERE CONDITION]
[GROUP BY [ROLLUP | CUBE] GROUP_BY_EXP]
[HAVING GROUP_CONDITION]
1️⃣ ROLLPUP
ROLLUP 연산자는 GROUP BY 절의 조건에 따라 전체 행을 그룹화 하여 각 그룹에 대해 부분합을 구하는 연산자이다.
예를 들어 교수 테이블의 교수를 학과별로 1차 그룹화하고, 이를 다시 직급에 따라 2차 그룹화 하면 다음과 같이 나타난다.

위의 데이터 DEPTNO 에 ROLLUP 연산자를 걸게 되면 다음과 같이 행이 추가된다.
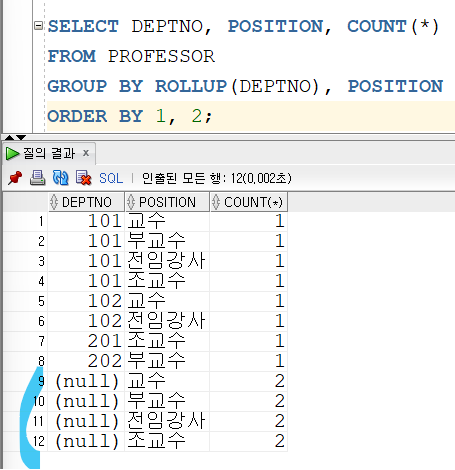
DEPTNO 를 사용하여 직급별 교수가 몇 명씩 있는지 확인해 볼 수 있다.
직급을 대상으로 하면 결과는 다음과 같이 달라진다.

이번에는 각 학과의 총 교수가 몇 명 있는지를 확인할 수 있다.
그렇다면 만약 이 두 컬럼을 묶어서 연산자를 적용해보면 어떨까?

질의 결과를 살펴보면 POSITON 을 묶었을 때처럼 학과에 소속된 교수의 수가 출력되었고
추가적으로 총 인원 수가 마지막 행에 추가된 것을 볼 수 있다.
2️⃣ CUBE
ROLLUP 에 의한 그룹 결과와 비슷한 형태로 출력되기는 하지만 한 가지 다른 점이 있다면,
ROLLUP 에 두 컬럼을 넣었을 때에는 한 쪽의 연산만 실행되고 전체 연산이 되었지만,
CUBE 는 두 컬럼에 대한 각각의 연산과 전체 연산을 하게 된다.

파란색 부분이 POSITION 의 부분합이고,
노란색 부분이 DEPTNO 의 부분합, 그리고 마지막 초록색 부분이 전체의 결과이다.
6. GROUPING 함수
SELECT COLUMN, GROUP_FUNCTION(COLUMN), GROUPING(COLUMN)
FROM TABLE
[WHERE CONDITION]
[GROUP BY [ROLLUP | CUBE] GROUP_BY_EXP]
[HAVING GROUP_CONDITION]
대상이 되는 컬럼이 ROLLUP 이나 CUBE 연산자로 생성된 그룹 조합에서 사용이 되었는지를 1 또는 0으로 반환하는 함수이다.
연산자에 사용이 되었을 경우에는 0이 반환되고, 사용되지 않았을 경우에는 1이 반환된다.
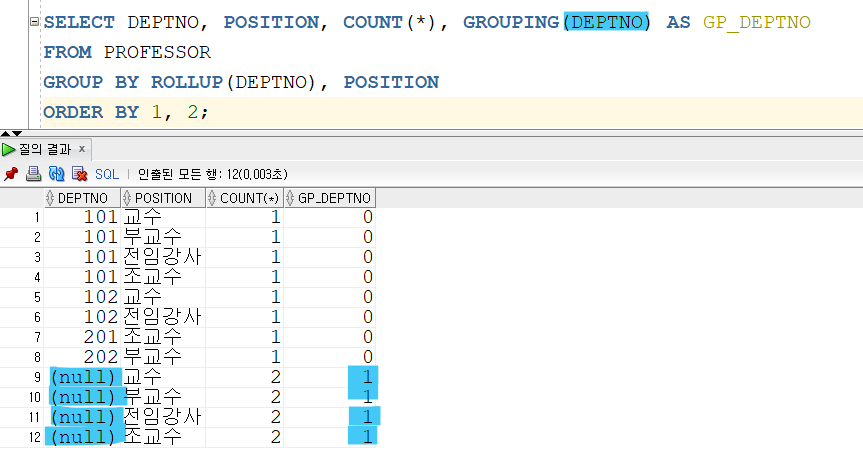
DEPTNO 를 연산자의 대상으로 사용되었는지 확인하기 위해 추가하여 보았다.
GROUP BY 절에서 ROLLUP 의 대상은 현재 DEPTNO 이다.
때문에 질의 결과에서도 DEPTNO 가 NULL 인 부분합이 출력되었다.
이에 따라 GROUPING 에서도 DEPTNO 가 사용되었다는 것을 인식하여 1을 출력하게 된 것이다.

둘 이상을 확인해 보아도 다음과 같이 확인이 가능하다.

CUBE 연산자와 ROLLUP 연산자의 차이도 확실히 구분 가능하다.
7. HAVING
GROUP BY 절에 생성한 그룹화 된 데이터를 대상으로 조건을 적용하는 절이다.
이 절에는 WHERE 절에서 해결하지 못하는 집계 함수를 사용하는 것이 성능상 효과적이다.
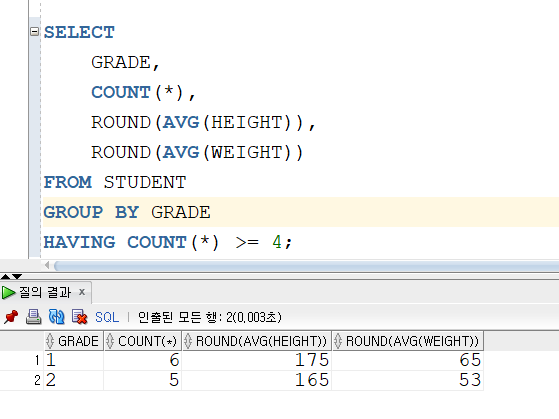
예를 들어 학생 수가 4명 이상인 학년에 대하여 학년, 학생 수, 평균 키, 평균 몸무게를 출력하기 위해서는 어떻게 쿼리를 짜면 될까?
학년을 기준하기 때문에 GROUP BY 절에는 GRADE 가 들어가면 된다.
또한 그 학년 중에서도 학생 수가 4명을 넘어야 하기 때문에 HAVING 절에는 해당 조건을 추가하면 된다.
📌 WHERE 절과 HAVING 절의 차이
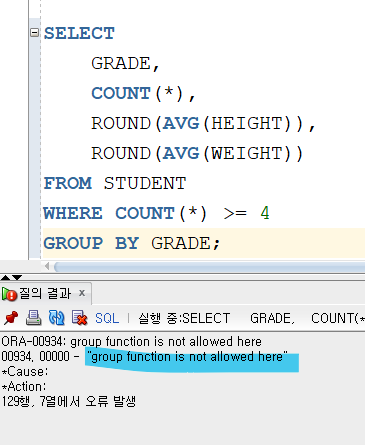
WHERE 절은 그룹화 전에 먼저 조건을 실행하기 때문에 그룹화 대상을 먼저 줄여주는 역할을 하게 된다.
하지만 마찬가지로 그룹화 전이기 때문에 집계 함수와 관련한 조건을 실행할 수 없다는 단점이 생긴다.
이때 HAVING 이 쓰이기 되는 것이다.
위의 내용을 WHERE 절에 조건으로 실행하면 다음과 같은 결과를 보게 된다.
'SQL > ORACLE' 카테고리의 다른 글
| SQL HR 예제 문제 풀이 1 (1) | 2022.11.04 |
|---|---|
| ORACLE SQL DEVELOPER 사이드바(접속) 보이게 하기 (0) | 2022.11.04 |
| 데이터 타입 변환 (0) | 2022.10.28 |
| SQL 단일 행 함수 (0) | 2022.10.26 |
| 정렬 SORTING (0) | 2022.10.24 |



